Apache Kafka in Five Minutes
What is Apache Kafka?
- Framework for building data pipelines and stream-based applications
- Fault tolerant, resilient
- Very high throughput
- Horizontal scalable
- Integrates well with Big Data frameworks like Apache Flink or Apache Spark
- Apache project ⇒ Apache license (i.e. OS software)
Common use cases
- Messaging systems (e.g. loosed coupled microservices communication)
- Gathering metrics from different locations (e.g. IoT)
- Collecting application logs
- Stream processing / transformation
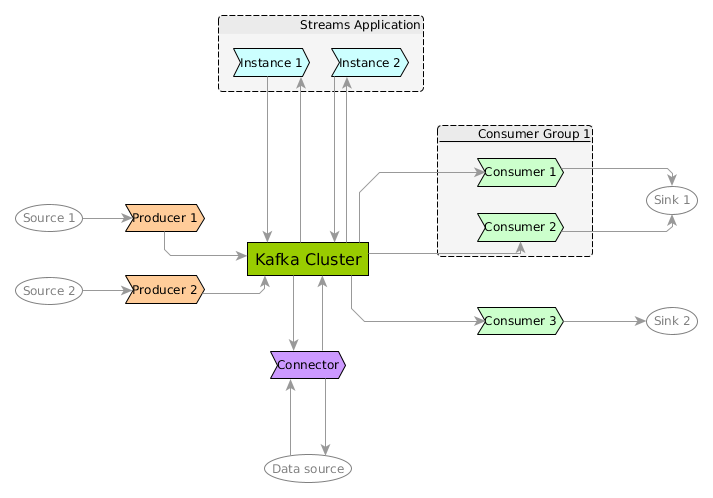
Components
Inside the cluster
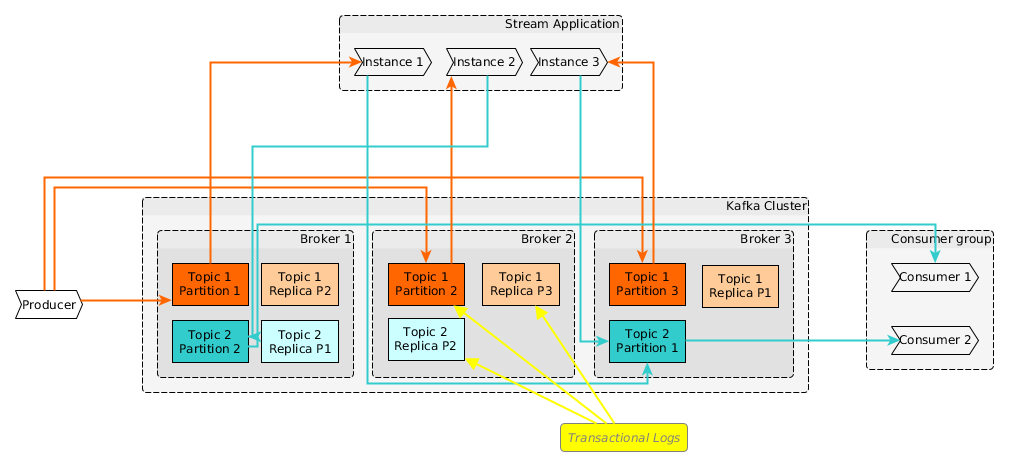
Logs
- Each partition / replica = transactional log
- Data in log is immutable
- Each message in log gets unique id (offset)
- Offsets are per partition
- Message order guarantee within partition
- Data is temporarily kept (thus messages are replayable)